Chinese-LLaMA-Alpaca-2部署
前言
之前部署的ChatGLM用来当私人助手还行,但是要是把他当做聊天对象的话真的不是一般的出戏
于是我在网上又找到了一款新模型「Chinese-LLaMA-Alpaca-2」
在初步测试之后,用来聊天是基本没有问题的(测试参数为7B 4bit量化),要是使用13B全精度推理应该会好很多
注:这里使用的是二代版本而不是一代版本,一代采用的是Lora权重+基底LLaMA,需要手动合并并且无法商用,二代采用基于Meta发布的可商用大模型Llama-2开发,遵守相关协议下可以商用
介绍
官方介绍:
更多介绍请移步至项目地址
部署
这里有中文LLaMA-2和Alpaca-2两个模型供大家选择,因为我已经有ChatGLM,只需要一个能聊天的AI,所以我部署的是Alpaca-2
下面是两个模型的对比区别:
| 对比项 | 中文LLaMA-2 | 中文Alpaca-2 |
|---|---|---|
| 模型类型 | 基座模型 | 指令/Chat模型(类ChatGPT) |
| 已开源大小 | 1.3B、7B、13B | 1.3B、7B、13B |
| 训练类型 | Causal-LM (CLM) | 指令精调 |
| 训练方式 | 7B、13B:LoRA + 全量emb/lm-head 1.3B:全量 | 7B、13B:LoRA + 全量emb/lm-head 1.3B:全量 |
| 基于什么模型训练 | 原版Llama-2(非chat版) | 中文LLaMA-2 |
| 训练语料 | 无标注通用语料(120G纯文本) | 有标注指令数据(500万条) |
| 词表大小[1] | 55,296 | 55,296 |
| 上下文长度[2] | 标准版:4K(12K-18K)长上下文版:16K(24K-32K) | 标准版:4K(12K-18K)长上下文版:16K(24K-32K) |
| 输入模板 | 不需要 | 需要套用特定模板[3],类似Llama-2-Chat |
| 适用场景 | 文本续写:给定上文,让模型生成下文 | 指令理解:问答、写作、聊天、交互等 |
| 不适用场景 | 指令理解 、多轮聊天等 | 文本无限制自由生成 |
[1] 本项目一代模型和二代模型的词表不同,请勿混用。二代LLaMA和Alpaca的词表相同。
[2] 括号内表示基于NTK上下文扩展支持的最大长度。
[3] Alpaca-2采用了Llama-2-chat系列模板(格式相同,提示语不同),而不是一代Alpaca的模板,请勿混用。
[4] 不建议单独使用1.3B模型,而是通过投机采样搭配更大的模型(7B、13B)使用。
大家根据自己的需求选择即可,因为官方没有提供4bit量化模型,所以我选择7B模型+在线量化的方式部署
如果大家手头有原版Llama-2模型基底,则可以只下载官方的Lora模型,完成合并即可
我这里为了方便起见选择「完整Chinese-Alpaca-2-7B模型」
官方目前提供三种模型下载方式:百度网盘、Google云盘、Huggingface
后两种下载方法在国内无法通过正常方式使用,有条件的朋友推荐后两种,当然如果你有百度网盘会员也可以采用第一种方式下载
长上下文版模型,官方推荐以长文本为主的下游任务使用,有需求的朋友也可以选择这类模型
下载模型
这里采用Huggingface下载方式
在合适位置使用git进行clone
1 | GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/hfl/chinese-alpaca-2-7b |
模型总共有13多G,所以为了保险起见,这里跳过clone lfs文件,等待clone完成。
clone完成后手动在https://huggingface.co/hfl/chinese-alpaca-2-7b仓库内下载有LFS标记的模型文件和tokenizer.model文件
下载完成后建议手动对LFS模型文件进行SHA256校验
注:请保证下载的模型名与仓库内的模型名称一致(部分下载软件可能会对文件进行重命名操作)
配置用户交互界面
这里采用对用户比较友好的text generation webui作为用户交互界面
首先将仓库clone至本地(请勿包含中文路径)
1 | git clone https://github.com/oobabooga/text-generation-webui |
clone 完成运行根目录下的start_windows.bat启动安装脚本
注:安装请保证网络环境优秀!!!优秀的网络环境可以节省至少一半以上的安装时间!!!
安装脚本启动后会依次安装conda,Pytorch等环境以及python依赖,需要10-20分钟左右
Nvidia显卡记得安装对应的CUDA程序https://developer.nvidia.com/cuda-downloads
等待安装完成…
启动模型
一切就绪后,将下载好的模型文件夹放入text-generation-webui根目录下models文件夹
运行start_windows.bat脚本启动UI界面
等待一会,当出现Running on local URL: http://127.0.0.1:XXXX 时访问该地址
在打开的网页中,选择Model,在Model中下拉选择已下载的模型,勾选load-in-4bit,然后点击Load加载模型
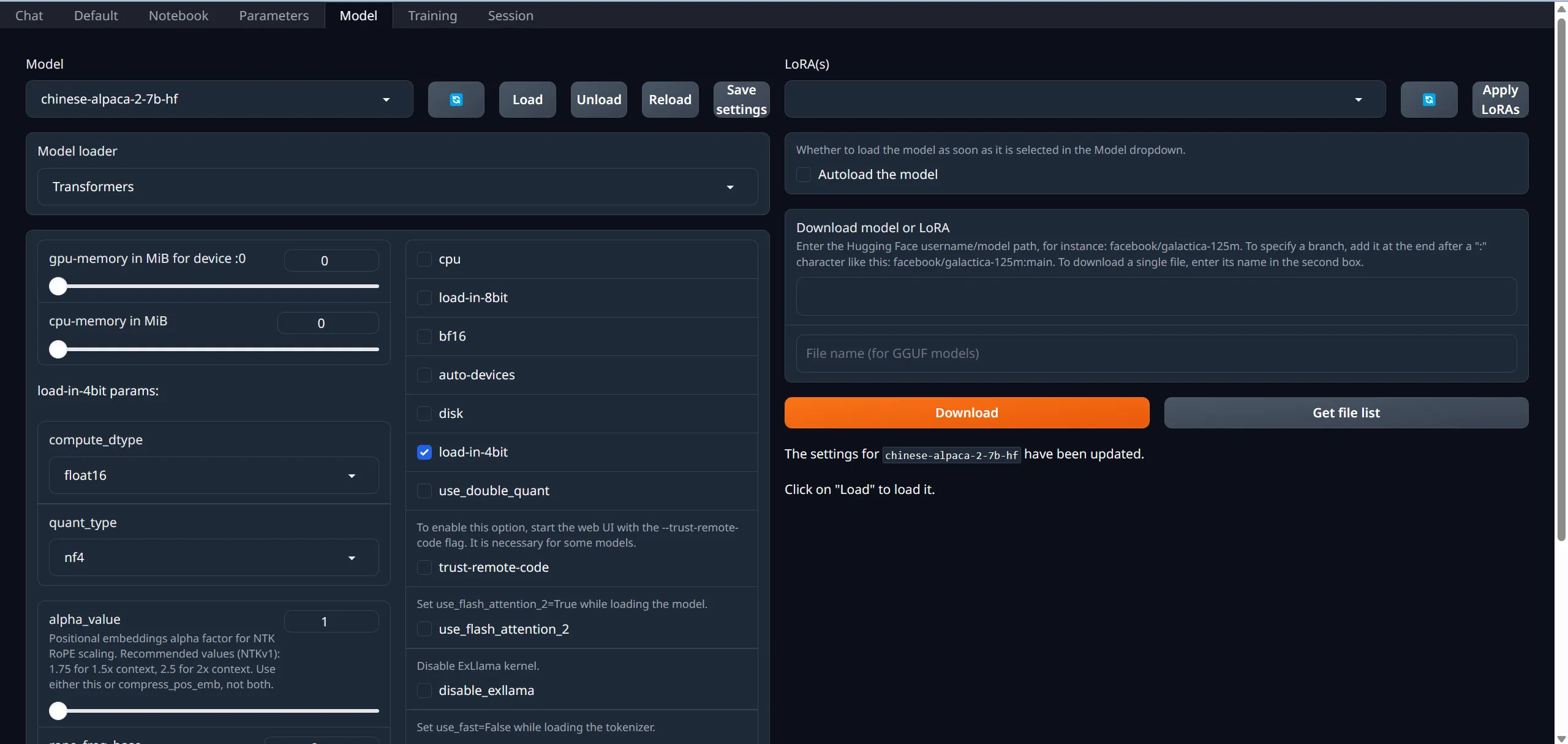
模型配置
选择Parameters,
Generation
这里你可以配置模型的各项参数,temperature,top_p等等
官方也有预设可以提供直接选择
- 对于Instruct(指示模式):Divine Intellect, Big O, simple-1, Space Alien, StarChat, Titanic, tfs-with-top-a, Asterism, Contrastive Search (only works for the Transformers loader at the moment).
- 对于Chat(聊天模式):Midnight Enigma, Yara, Shortwave.
当然你也可以点击旁边的骰子图标来随机一个
Character(适用于Chat与Chat-instruct模式)
这里可以设置AI的人设,你可以将它设置为你的小助手,或者是猫娘(bushi,亦或是一起探险的好伙伴
Context内可以填写AI的prompt,至于怎么写prompt,就要看各位的自我发挥咯~
当然也有生成prompt的相关网站,https://toolsaday.com/writing/character-generator 这个网站感觉还行
设置完成后可以选择将人设其保存下来,方便以后使用
Greeting内可以填写AI的开场白,或者是故事背景,自我发挥即可
最右边还可以设置AI和你的个性头像,加深带入感
Instruct template( 适用于Chat-instruct与Instruct模式)
这里也是设置AI的人设选项卡,下面为官方的设置
依次选择Parameters-> Instruction template,在Instruction template中下拉选择Llama-v2,并将Context输入框中的Answer the questions.提示语替换为You are a helpful assistant. 你是一个乐于助人的助手。
设置完成后也可以保存,方便以后使用
使用
选择Chat选项卡,进入聊天页面(当然你也可以选择default和notebook,只是我个人觉得Chat页面更好用而已)
这里简单介绍输入框左边的菜单选项
Start new chat:顾名思义,开始一段新对话
Send dummy message、Send dummy reply:这两说白了就是伪造聊天记录,一个伪造你发送的内容,一个伪造回复你的内容,并没有经过模型处理,但也不能完全认定为伪造,有时候对调整AI对话走向有正向的效果
Impersonate:让AI根据上下文推理出你需要说的话(说白了就是自导自演哈哈哈哈,或者当你词穷和无语时,试试让AI自导自演一下?)
Continue:继续未完成的对话,当对话一次可能太长导致生成中断,可以使用它来继续生成对话
Regenerate:给AI一次重新组织语言的机会
下方是官方的解释:
其他的各种玩法就需要大家自己自行探索了~
后记
请遵守当地的法律法规,请勿将AI用于非法用途!!!

Use this card to join MyBlog and participate in a pleasant discussion together .
Welcome to GoodBoyboy 's Blog,wish you a nice day .




